How to reduce AI coding mistakes in production
How to reduce AI coding mistakes in production
You reduce AI coding mistakes in production by treating model output as a suggestion, not a merge. The fastest-shipping teams in 2026 layer four cheap guardrails: strict types, custom lint rules, an eval suite that runs per PR, and a human gate before main. Each layer catches a different class of failure, and together they cut hallucinated APIs, mismatched types, ignored edge cases, and silent security gaps before they reach users.
The trap is treating Cursor, Claude Code, or Copilot as a senior engineer. They are not. They are extremely fast junior engineers with photographic recall of yesterday's docs and zero memory of what shipped to your repo last week. The skill is building a workflow where their speed is captured and their failure modes are caught early.
The five failure modes that actually reach production
We've watched hundreds of AI-generated PRs land in real codebases over the past 18 months. The mistakes cluster into five repeating shapes. Once you can name them, you can build a check for each.
1. Hallucinated APIs
The model invents a function that doesn't exist. stripe.subscriptions.cancelImmediately() instead of the real stripe.subscriptions.cancel({ invoice_now: true }). supabase.auth.signInWithMagicCode() when the actual SDK uses signInWithOtp(). The code parses, looks right, and fails the first time real traffic hits it.
This happens because the model fills gaps with plausible names. The fix is type-checking against the actual installed SDK, not the model's memory of it.
2. Outdated dependencies and patterns
The training cutoff lies to you. Claude or Cursor confidently writes Next.js 13 pages/ router code in a Next.js 15 App Router project. It uses React 17 class components when the codebase is React 19. It calls deprecated Node APIs that throw at runtime.
You see this most in projects with rapid framework churn: Next.js, React Server Components, Drizzle, Bun, Hono. The fix is project-level rules that pin the model to your version.
3. Mismatched types
The function signature looks right. The return shape is wrong. The model returns { user: User } when the caller expects { data: User, error: null }. TypeScript catches some of this, but only if your types are strict and your boundaries are explicit. Loose any types let the mismatch through.
We see this constantly at API boundaries: tRPC procedures, Supabase RPCs, REST handlers. The fix is noUncheckedIndexedAccess, noImplicitAny, and Zod schemas at every edge.
4. Ignored edge cases
The model writes the happy path with confidence. Empty arrays, null users, 401 responses, timezone-naive dates, race conditions during double-clicks: all skipped unless you prompt for them. Then it writes them once you ask, but you have to know to ask.
This is the failure mode that produces the most production bugs because it ships clean. There is no compile error, no lint warning, just a Cannot read property 'name' of undefined at 3am.
5. Security gaps that Claude and Cursor miss
The hard one. SQL injection through unsanitized template literals in raw queries. XSS through dangerouslySetInnerHTML with user input. Missing CSRF tokens on mutating endpoints. Hardcoded API keys in client bundles. Auth checks that compare strings instead of cryptographic equality.
Modern AI tools are better than they were in 2024, but they still miss context-dependent vulnerabilities constantly. A prompt that says "build a user search endpoint" produces an endpoint without rate limiting, without input validation, and often without an authorization check at all.
The four-layer guardrail stack
This is the working stack we recommend for any team shipping AI-generated code to real users. None of it is expensive, and most of it runs on every PR automatically.
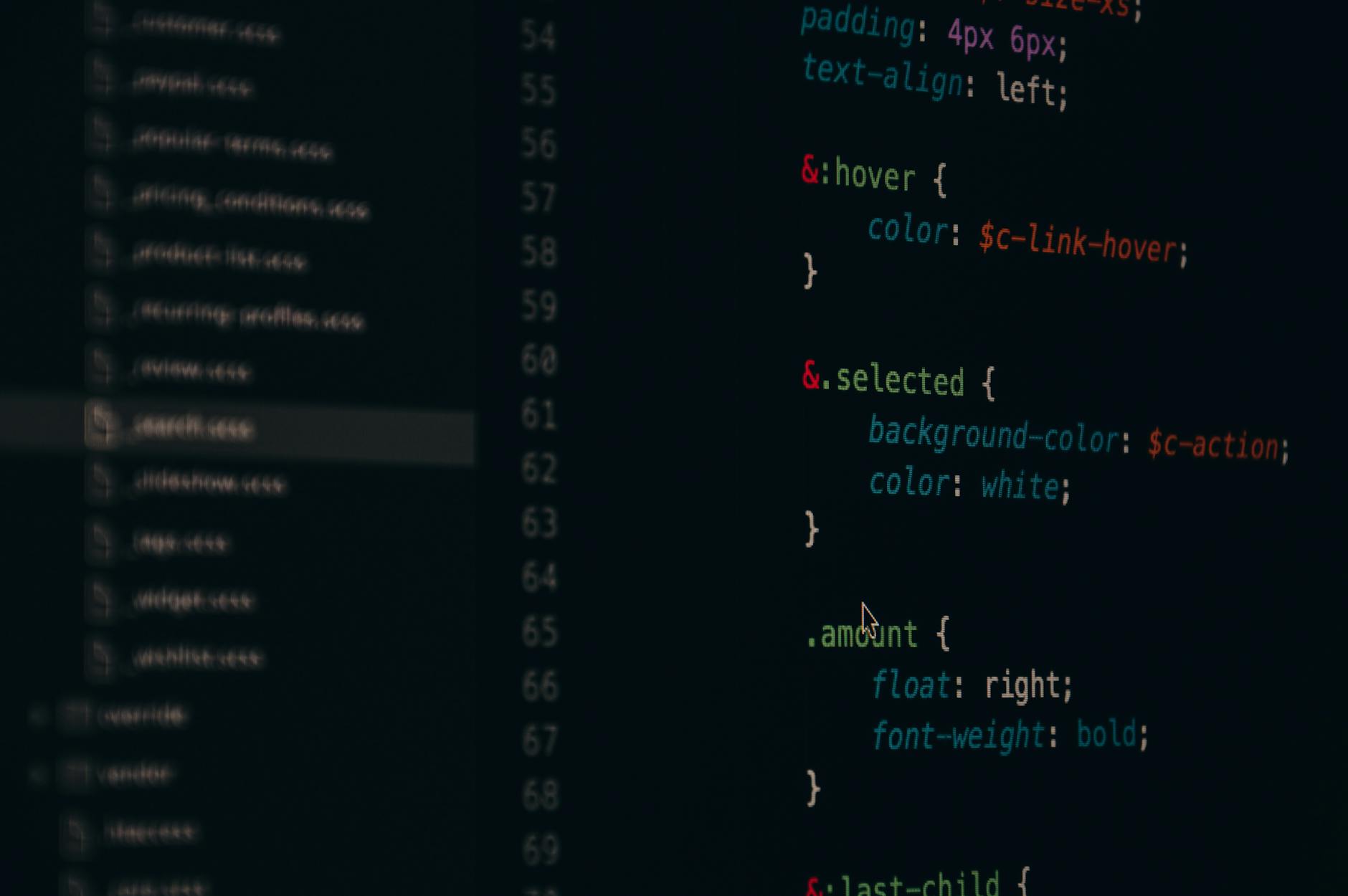
Layer 1: strict types as the first reviewer
Turn TypeScript up to maximum strictness. strict: true is the floor. Add noUncheckedIndexedAccess, noImplicitOverride, noFallthroughCasesInSwitch. Then enforce Zod (or Valibot, or Effect/Schema) at every API boundary, every form, every database read.
The model can lie in prose. It cannot lie to tsc. The compiler is your cheapest, fastest reviewer, and it runs in the IDE in real time. A 3-minute setup investment kills 40% of hallucinated API calls before the PR even opens.
Layer 2: custom ESLint rules
Default ESLint catches generic mistakes. Custom rules catch your team's mistakes. Write a rule that bans dangerouslySetInnerHTML without an accompanying sanitize() call. Ban raw process.env access outside lib/env.ts. Ban any in PR diffs even if it exists elsewhere.
The AI-assisted refactoring playbook covers how to build these rules incrementally. Start with three rules that block your three most common production bugs. Add one per quarter.
Layer 3: comprehensive tests, including an eval suite
Unit tests catch the obvious. The interesting layer is the eval suite: a set of prompts plus expected behaviors that run on every PR. Not testing your code, testing how the model behaves against your codebase.
For example, an eval that says: "given this Cursor prompt and our repo, the model must produce a function that handles null users." Run it against the PR's branch. If the model now produces buggy code that it didn't produce before, the eval fails and the PR is blocked. Tools like Promptfoo, Inspect, and Braintrust make this realistic to set up in a day.
We dig into the eval-per-PR pattern in our autonomous coding agents writeup. The core idea: your CI should test the model, not just the diff.
Layer 4: human gate before main
The non-negotiable. No AI-generated PR auto-merges. A real engineer reads the diff, runs the code locally, and signs off. This is not optional, and it is not paranoid. It is the cheapest insurance you can buy.
The catch: the reviewer needs to know what to look for. They need to read the diff with the five failure modes in mind, not skim it for "looks fine." A reviewer who clicks "Approve" after 20 seconds is a worse signal than no reviewer at all.
Comparison: safeguards by cost, coverage, and friction
The right stack depends on team size and risk tolerance. Here's how the common safeguards compare on the dimensions that actually matter when you're choosing what to install first.
| Safeguard | Setup cost | Per-PR friction | Catches | Misses |
|---|---|---|---|---|
| Strict TypeScript + Zod | 1-2 days | Zero (runs in IDE) | Type mismatches, hallucinated APIs, shape errors | Logic bugs, security gaps |
| Custom ESLint rules | 1 day per rule | Zero (runs on save) | Project-specific anti-patterns, banned APIs | Anything you haven't written a rule for |
| Unit + integration tests | Ongoing | 5-30 min (write tests) | Logic regressions, edge cases you remembered | Edge cases you didn't remember |
| Eval suite per PR | 1-2 days initial | 1-5 min CI run | Model behavior drift, prompt regressions | Code-level bugs the eval doesn't simulate |
| Mandatory human review | Zero setup | 10-30 min per PR | Context-dependent issues, security gaps, intent mismatch | Whatever the reviewer skims past |
| Semgrep / Snyk security scan | 2-4 hours | 30s CI run | Known CVE patterns, common injection shapes | Novel logic-level security flaws |
| AI code review (CodeRabbit, Greptile) | 1 hour | Zero (async comment) | Inconsistencies, missing tests, dead code | Anything that looks plausible to another model |
The pattern most disciplined teams converge on: layers 1, 2, 4 from the prevention stack plus Semgrep on every PR. Eval suites become worth it once you've shipped enough AI-generated code that prompt regressions cost you real time.
Prompting practices that prevent mistakes upstream
Guardrails catch bugs. Better prompts prevent them. Three habits cut AI mistakes by roughly half before the code is even written.
Specify edge cases in the prompt. "Build a user search endpoint" produces a happy-path endpoint. "Build a user search endpoint that handles: empty query, query with SQL meta-characters, 0 results, 10,000+ results, unauthenticated user, rate-limited caller" produces something close to production-ready. The model handles every case you name and skips every case you don't.
Anchor to your stack version. Start every Cursor or Claude Code session by pasting your package.json dependencies. The model will pattern-match to those versions instead of defaulting to its training data. For Cursor specifically, configure .cursorrules with the exact versions. This single habit kills most outdated-pattern bugs.
Run a verification step. After the model writes code, ask it: "What edge cases did you skip? What types are loose? What would break under concurrent requests?" The same model that wrote the buggy code will frequently find the bugs when asked. This is the prompt-as-spec / verify-by-default loop that defines how AI-native engineers actually work.
For a deeper take, see our AI-native engineering ROI breakdown, which has the workflow patterns that separate 3x teams from 1.1x teams.
What to do this week
If you're shipping AI-generated code and want to reduce mistakes, here's the order that has the best return on time invested.
- Turn TypeScript strictness to max. Run
tsc --noEmitand fix what breaks. One day of work, permanent payoff. - Add Zod schemas at every API boundary. Start with your three highest-traffic endpoints.
- Write three custom ESLint rules for your three most common production bugs.
- Add Semgrep or Snyk to CI. Free tier is sufficient for most teams.
- Write a one-page "AI code review checklist" and require reviewers to skim it before approving. Cover the five failure modes from this post.
- Once those are in place, look at an eval suite. Promptfoo is the easiest starting point.
If your bottleneck is reviewer capacity (you have AI generating PRs faster than humans can review them), the answer isn't more AI. The answer is more humans who know how to read AI-generated diffs. Every engineer on Cadence is AI-native by default, vetted on Cursor / Claude / Copilot fluency, prompt-as-spec discipline, and verification habits before they unlock bookings. That includes the muscle of reading an AI diff with the failure modes in mind, which is the actual skill you need on review duty.
If you want a recommendation on whether your next feature should be built, bought, or booked out, run it through our Build/Buy/Book tool and get a 60-second answer.
Where Cadence fits
There is no shortcut around the four-layer stack. Tools don't replace the discipline of strict types, custom rules, tests, and human review. But the team applying that discipline matters as much as the tools.
If you're hiring this week and need someone who can land AI-generated PRs that don't break production, Cadence shortlists 4 vetted engineers in 2 minutes. Every engineer is AI-native by baseline (Cursor, Claude Code, Copilot fluency scored in a voice interview), and the 48-hour free trial means you test the actual code-review instincts before you commit to a week.
Pricing is $500/week for junior cleanup work, $1,000/week for mid-level feature shipping, $1,500/week for senior architecture and refactor work, and $2,000/week for lead-level systems decisions. Weekly billing, cancel any week, no notice period. Our Cursor agent mode in production guide covers the workflow patterns the senior tier uses to ship reliably with autonomous agents.
FAQ
Why does AI-generated code fail in production more than human-written code?
It doesn't always, but it fails differently. AI code is over-confident on the happy path and under-attentive to edge cases, security context, and version-specific APIs. Human code has more typos and slower velocity, but humans naturally ask "what happens if this is null?" while models ship the version that assumes it isn't.
Can I trust Claude Code or Cursor to auto-merge PRs?
Not in any system with real users. Even with strict types, lint, and tests, the model misses context that a human reviewer catches in 30 seconds: a misnamed variable that compiles fine, a security check that's syntactically present but logically wrong, a feature spec that the model misinterpreted. Use AI as a suggestion engine and keep humans on the merge gate.
What's the single highest-ROI guardrail to add first?
Strict TypeScript with Zod at API boundaries. One day of setup, runs in the IDE in real time, catches the largest class of AI mistakes (hallucinated APIs, shape mismatches, missing fields) before the PR opens. Everything else is the second priority.
How do I catch AI security mistakes that Claude and Cursor miss?
Run Semgrep or Snyk on every PR for known patterns, train reviewers on the OWASP top 10 with explicit "AI tends to skip this" callouts, and put auth checks behind a custom ESLint rule that flags any handler that doesn't import your auth middleware. Don't rely on the model to remember security context across files.
Do AI code review tools like CodeRabbit replace human review?
No. They catch a useful slice (missing tests, dead code, inconsistent naming), but they share blind spots with the model that wrote the code. Use them as a third reviewer that runs for free, not as a replacement for a human who understands your product and your users.
Fullstack developer at withRemote. Ships across the stack — TypeScript, Node, Postgres, Vercel. Writes on shipping speed and pragmatic architecture.